


Key Takeaways
- Deep learning models like BERT and RoBERTa are effective in restoring missing characters in ancient texts.
- Combining NLP and CV approaches can enhance accuracy in the restoration of inscriptions, achieving performance improvements up to 88.5% accuracy.
- Challenges remain with character recognition due to historical variations and the complexity of ancient writing styles.
Advancements in Inscription Restoration
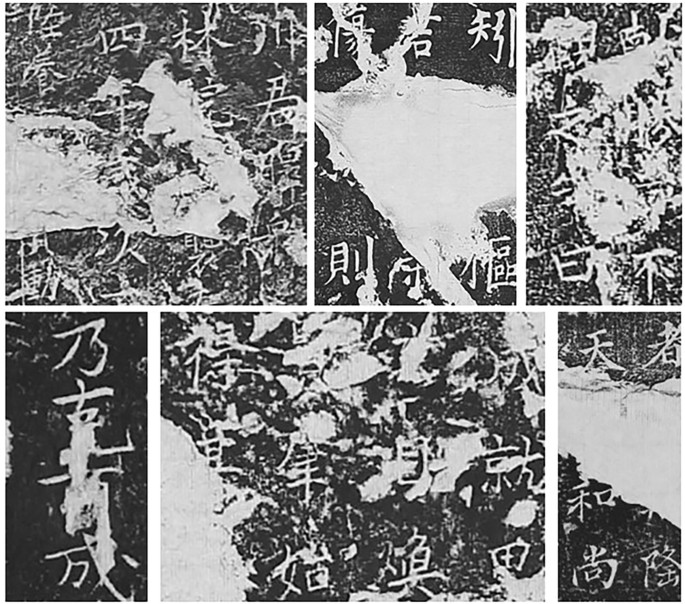
Machine learning, particularly deep learning, is increasingly used to address challenges in restoring ancient inscriptions with missing characters. Two prominent branches of this technology are Natural Language Processing (NLP) and Computer Vision (CV), both demonstrating considerable promise in this field.
Transformers have emerged as a leading architecture for deep learning tasks, notably in restoring inscriptions with missing characters. BERT and RoBERTa, two prominent Transformer models, excel in natural language tasks. For example, the Pythia model integrates Long Short-Term Memory (LSTM) networks with attention mechanisms, achieving a predictive accuracy of 30.1%. Its successor, Ithaca, further improved this to 72% with epigrapher collaboration.
Enhancements in ancient text restoration have been realized with models like SikuBERT and SikuRoBERTa, which have outperformed standard BERT models in processing ancient Chinese texts. Furthermore, various deep learning techniques, including multi-task learning and ensemble methods, have been applied to improve outcomes in tasks ranging from Babylonian script recovery to the historical records of the Joseon Dynasty.
CV models also play a critical role, specifically in the restoration of partially damaged characters. Convolutional Neural Networks (CNNs) and Generative Adversarial Networks (GANs) are frequently utilized to enhance the restoration of inscriptions. While CNNs effectively extract local features, GANs, which leverage competitive learning between generators and discriminators, have proven particularly suitable for image-based text restoration, capable of filling in significant gaps within text images.
The integration of both NLP and CV models is vital for comprehensive restoration. A proposed technical framework combines predictions from these models to inform expert decisions about the most probable missing characters. By utilizing an improved F1 score that balances the outputs from NLP and CV models, restoration accuracy is significantly enhanced.
Data collection for these models involves meticulous processing steps, including the augmentation of traditional Chinese characters to improve recognition capabilities. With a focus on addressing the challenges posed by diverse historical writing styles and damaged texts, contemporary techniques aspire to not only recover missing inscriptions but also preserve the cultural heritage encapsulated within these ancient works.
Despite significant advancements, challenges persist in the realm of ancient inscription restoration, particularly concerning the recognition of characters and the varying styles across historical periods. Nonetheless, ongoing developments in machine learning technologies promise continued improvements in this essential field of study.
The content above is a summary. For more details, see the source article.











